Getting started¶
Let’s suppose that we want to calculate this integral: \(\int_0^1 \int_0^1 x \cdot y \, dx dy\).
This could be computed using mcquad.
>>> from skmonaco import mcquad
>>> mcquad(lambda x_y: x_y[0]*x_y[1], # integrand
... xl=[0.,0.],xu=[1.,1.], # lower and upper limits of integration
... npoints=100000 # number of points
... )
(0.24959359250821114, 0.0006965923631156234)
mcquad returns two numbers. The first (0.2496…) is the value of
the integral. The second is the estimate in the error (corresponding,
roughly, to one standard deviation). Note that the correct answer in
this case is \(1/4\).
The mcquad call distributes points uniformly in a hypercube and sums
the value of the integrand over those points.
The first argument to mcquad is a callable specifying the integrand.
This can often be done conveniently using a lambda function. The integrand must
take a single argument: a numpy array of length d, where d is the number of
dimensions in the integral. For instance, the following would be valid integrands:
>>> from math import sin,cos
>>> integrand = lambda x: x**2
>>> integrand = lambda xs: sum(xs)
>>> def integrand(x_y):
... x,y = x_y
... return sin(x)*cos(y)
If the integrand takes additional parameters, they can be passed to the
function through the args argument. Suppose that we want to evaluate the
product of two Gaussians with exponential factors alpha and beta:
>>> import numpy as np
>>> from skmonaco import mcquad
>>> f = lambda x_y,alpha,beta: np.exp(-alpha*x_y[0]**2)*np.exp(-beta*x_y[1]**2)
>>> alpha = 1.0
>>> beta = 2.0
>>> mcquad(f,xl=[0.,0.],xu=[1.,1.],npoints=100000,args=(alpha,beta))
(0.44650031245386379, 0.00079929285076240579)
mcquad runs on a single core as default. The parallel behaviour can be
controlled by the nprocs parameter. The following can be run in an
ipython session to take advantage of their timing routines.
>>> from math import sin,cos
>>> from skmonaco import mcquad
>>> f = lambda x,y: sin(x)*cos(y)
>>> %timeit mcquad(f,xl=[0.,0.],xu=[1.,1.],npoints=1e6,nprocs=1)
1 loops, best of 3: 2.26 s per loop
>>> %timeit mcquad(f,xl=[0.,0.],xu=[1.,1.],npoints=1e6,nprocs=2)
1 loops, best of 3: 1.36 s per loop
Complex integration volumes¶
Monte Carlo integration is very useful when calculating integrals over complicated integration volumes. Consider the integration volume shown in red in this figure:
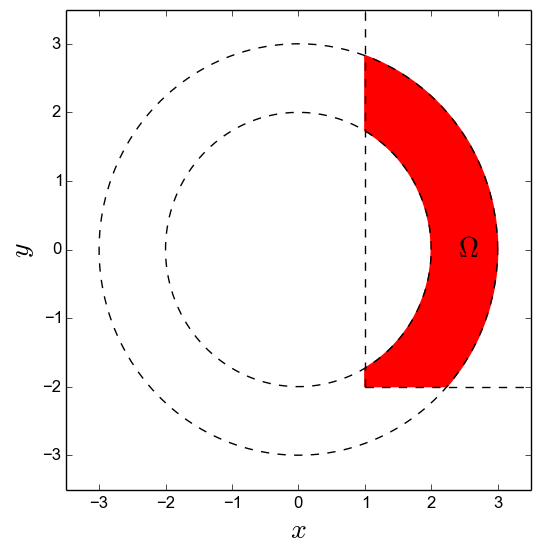
The integration volume is the intersection of a ring bounded by circles of radius 2 and 3, and a large square.
The volume of integration \(\Omega\) is given by the following three inequalities:
- \(\sqrt{x^2 + y^2} \ge 2\) : inner circle
- \(\sqrt{x^2 + y^2} \le 3\) : outer circle
- \(x \ge 1\) : left border of box
- \(y \ge -2\) : top border of box
Let \(\Omega\) denote this volume. Suppose that we want to find the integral of \(f(x,y)\) over this region. We can re-cast the integral over \(\Omega\) as an integral over a square that completely encompasses \(\Omega\). In this case, the smallest rectangle to contain \(\Omega\) starts has bottom left corner \((1,-2)\) and top right corner \((3,3)\). This rectangle is shown in blue in the figure below.
Then:
\(\iint_\Omega f(x,y) \, dx dy = \int_{-2}^3 \int_1^3 g(x,y) \,dx dy\)
where
\(g(x,y) = \left\{ \begin{array}{l l}f(x,y) & (x,y) \in \Omega \\ 0 & \mathrm{otherwise}\end{array}\right.\)
This is illustrated in the figure below, which shows 200 points randomly distributed within the rectangle bounded by the blue lines. Points in red fall within \(\Omega\) and thus contribute to the integral, while points in black fall outside \(\Omega\).
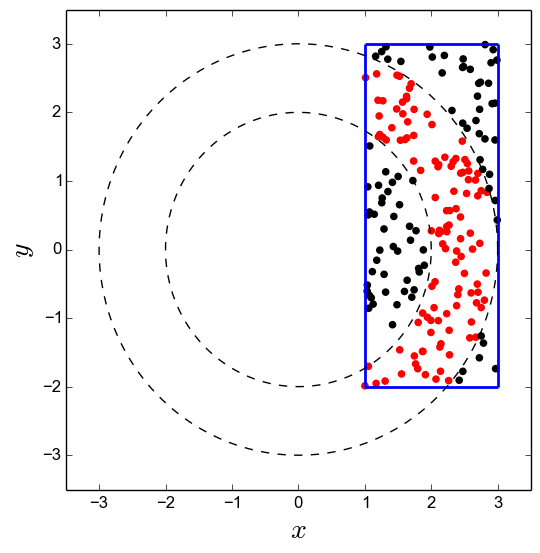
To give a concrete example, let’s take \(f(x,y) = y^2\).
import numpy as np
def f(x_y):
x,y = x_y
return y**2
def g(x_y):
"""
The integrand.
"""
x,y = x_y
r = np.sqrt(x**2 + y**2)
if r >= 2. and r <= 3. and x >= 1. and y >= -2.:
# (x,y) in correct volume
return f(x_y)
else:
return 0.
mcquad(g,npoints=100000,xl=[1.,-2.],xu=[3.,3.],nprocs=4)
# (9.9161745618624231, 0.049412524880183335)
Array-like integrands¶
We are not limited to integrands that return floats. We can have integrands that return array objects. This can be useful for calculating several integrals at the same time. For instance, let’s say that we want to calculate both \(x^2\) and \(y^2\) in the volume \(\Omega\) described in the previous section. We can do both these integrals simultaneously.
import numpy as np
def f(x_y):
""" f(x_y) now returns an array with both integrands. """
x,y = x_y
return np.array((x**2,y**2))
def g(x_y):
x,y = x_y
r = np.sqrt(x**2 + y**2)
if r >= 2. and r <= 3. and x >= 1. and y >= -2.:
# (x,y) in correct volume
return f(x_y)
else:
return np.zeros((2,))
result, error = mcquad(g,npoints=100000,xl=[1.,-2.],xu=[3.,3.],nprocs=4)
print result
# [ 23.27740875 9.89103493]
print error
# [ 0.08437993 0.04938343]
We see that if the integrand returns an array, mcquad will return two
arrays of the same shape, the first corresponding to the values of the
integrand and the second to the error in those values.
Importance sampling¶
The techniques described in the previous sections work well if the variance of the integrand is similar over the whole integration volume. As a counter-example, consider the integral \(\int_{-\infty}^\infty \cos(x)^2 e ^{-x^2/2}\,dx\). Only the area around \(x = 0\) contributes to the integral in a significant way, while the tails, which stretch out to infinity, contribute almost nothing.
We would therefore like a method that samples more thoroughly regions where the integral varies rapidly. This is the idea behind importance sampling.
To use importance sampling, we need to factor the integrand \(f(x)\) into a probability distribution \(\rho(x)\) and another function \(h(x)\). For the integrand described above, we can take \(\rho(x) = \frac{1}{\sqrt{2\pi}}e^{-x^2/2}\) (normal distribution) and \(h(x) = \sqrt{2\pi}\cos^2(x)\). We can then draw samples from \(g(x)\) and, for each sample, calculate \(h(x)\). This is done using the function mcimport:
>>> from skmonaco import mcimport
>>> from numpy.random import normal
>>> from math import cos,sqrt,pi
>>> result, error = mcimport(lambda x: sqrt(2.*pi)*cos(x)**2, # h(x)
... npoints = 100000,
... distribution = normal # rho(x)
... )
>>> result # Correct answer: 1.42293
1.423388348518721
>>> error
0.002748743084305
We see that mcimport takes at least three arguments, the first one being the function \(h(x)\), that is, the integrand divided by the probability distribution from which we sample, the second being the number of points and the third is a function that returns random samples from the probability distribution \(\rho(x)\). The numpy.random module provides many useful distributions that can be passed to mcimport. mcimport returns two numbers: the first corresponds to the integral estimate, and the second corresponds to the estimated error.
Multi-dimensional integrals¶
To look at a slightly more complicated example, let’s integrate \(f(x,y) = e^{-(y+2)}\) in the truncated ring described above. The integrand is largest around \(y = -2\), and decays very quickly:
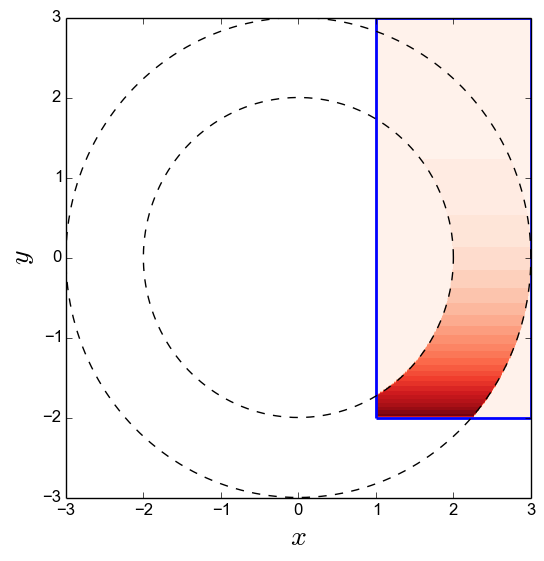
\(e^{-(y+2)}\) in the truncated ring.
It makes sense to try and concentrate sample points around \(y = -2\). We can do this by sampling from the exponential distribution (centered about \(y=-2\)) along y and uniformly along x (in the region \(1 \le x < 3\)), such that \(\rho(x,y) = \frac{1}{2}e^{-(y+2)}\), where the pre-factor of \(1/2\) arises from the normalisation condition on the uniform distribution along x. The distribution function that must be passed to mcimport must take a size argument and return an array of shape (size,d) where d is the number of dimensions of the integral. This could be achieved with the following function:
from numpy.random import exponential, uniform
def distribution(size):
"""
Return `size` (x,y) points distributed according to a uniform distribution
along x and an exponential distribution along y.
"""
xs = uniform(size=size,low=1.0,high=3.0)
ys = exponential(size=size,scale=1.0) - 2.
return np.array((xs,ys)).T
distribution(100).shape
# (100,2)
This is what 200 points distributed according to distribution look like. Points that fall within \(\Omega\) are colored in red, and those that fall outside are colored in black. Evidently, points are concentrated about \(y = -2\), such that this region gets sampled more often.
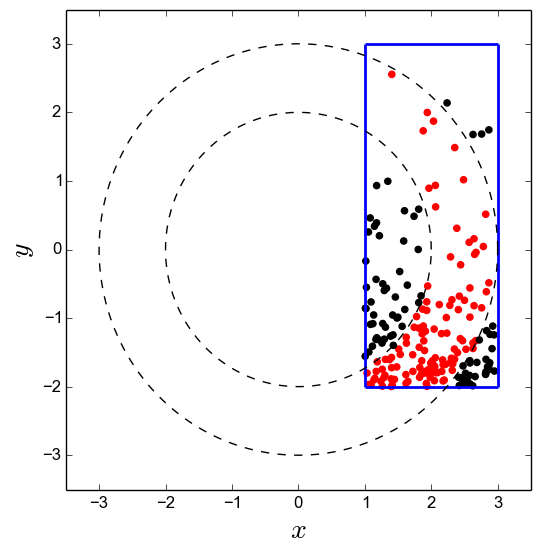
The function to sample is \(f(x,y) = 2\) (the factor of 2 cancels the 1/(high-low) prefactor in the uniform distribution) if \(f(x,y) \in \Omega\) and 0 otherwise.
def f(x_y):
"""
The integrand.
"""
x,y = x_y
r = np.sqrt(x**2 + y**2)
if r >= 2. and r <= 3. and x >= 1. and y >= -2.:
# (x,y) in correct volume
return 2.
else:
return 0.
mcimport(f,1e5,distribution,nprocs=4)
# (1.18178, 0.0031094848254976256)
Choosing a probability distribution¶
Generally, it is far from obvious how to split the integrand \(f(x)\) into a probability distribution \(\rho\) and an integration kernel \(h(x)\). It can be shown [NR] that, optimally \(\rho \propto |f|\). Unfortunately, this is likely to be very difficult to sample from.
The following recipe is relatively effective:
- If the integrand decays to 0 at the edge of the integration region, find a distribution that has the same rate of decay, or decays slightly slower. Thus, if, for instance, the integrand if \(p(x) e^{-x^2}\), where \(p(x)\) is a polynomial, sample from a normal distribution with \(\sigma=1/\sqrt{2}\), or slightly less if \(p(x)\) contains high powers that delay the onset of the exponential decay.
- Locate the mode of your distribution at the same place as the mode of the integrand.
The following two cases should be avoided:
- The probability distribution should not be low in places where the integrand is large.
- Somewhat less importantly, the probability distribution should not be high in regions where the variance of the integrand is low.
| [NR] | Press, W. H, Teutolsky, S. A., Vetterling, W. T., Flannery, B. P., Numerical Recipes, The art of scientific computing, 3rd edition, Cambridge University Press (2007). |